 Billets d'humeur
Billets d'humeur
« Digital nomad », une option pour vous ?
« Digital nomad » ! Caroline Loisel et Tristan Bochu échangent sur cette expérience. 4 min
Retrouvez tous nos articles autour de l’actualité et du marché IT. Vous souhaitez que l’on aborde un sujet en particulier ou publier sur notre blog ? Formulez votre demande ici, nous vous recontacterons rapidement.
Billets d'humeur
 Métiers IT
Métiers IT
 Guide du freelance
Guide du freelance
 Talents IT
Talents IT
 Talents IT
Talents IT
 Actualités Informatiques
Actualités Informatiques
 Free-Workers life
Free-Workers life
 Actualités Informatiques
Actualités Informatiques
 Actualités Informatiques
Actualités Informatiques
 Actualités Informatiques
Actualités Informatiques
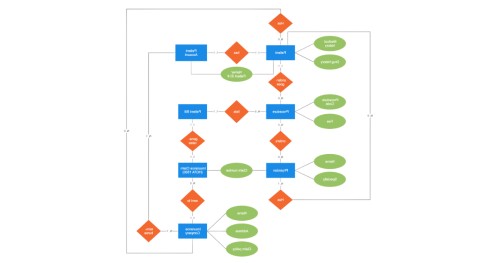 Actualités Informatiques
Actualités Informatiques
 Talents IT
Talents IT
 Actualités Informatiques
Actualités Informatiques


